Which Big Data Tools are the Best for Building Your First Project?
You often read and hear similar questions from developers and students who are eager to participate in Big Data projects and invest their time or even capital in a study of tools that would allow them to start a project. A lot of materials are devoted to this subject, but today I will share my three years` experience in working with Big Data tools.
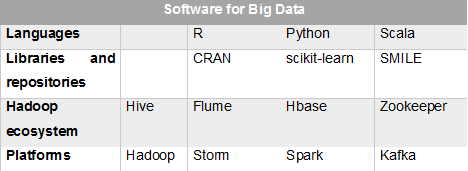
Let’s start with a choice of language development tools for the primary process of data operation. In many cases initial analytics projects focus on fast achievement of analysis results rather than on development of effective software products. In this case R, a language environment, is a good choice.
Today the language platform Microsoft R Open allows developing the most complex Big Data operation processes using powerful package libraries among which CRAN (Comprehensive R Archive Network) is mostly known. R is a good development language option since it can be set up on any computer and has an open-source framework R Studio.
The Python programming language can compete with the R language environment in the Big Data field. Python language is supported by almost all platforms for Big Data development and has a large number of effective libraries for implementation and use of different algorithms, among which the most popular are Scikit-learn and Theano. We should note that a modern engineering approach to data processing applies ready implementations of algorithms and converts a project into a pipeline of calls to library procedures. The development of such universal data transformation algorithms is normally an area of research projects performed by groups of mathematicians and outstanding programmers and lies beyond the scope of analytical projects. We will consider this topic sometime later.
As for Python, it allows using a flexible environment TensorFlow that combines separate processing modules. It represents the whole data processing process with an acyclic graph the edges of which describe data transfer in the form of multidimensional arrays – tensors. Keras is a Python library able to launch a project for training a deep learning neural network or a recurrent network described in a compact code. In addition, we can use the Scala language implemented on a standard JVM (Java Virtual Machine) that has become a core language for development on the Apache Spark platform. There are also several libraries of advanced algorithms, the most popular today being SMILE (Statistical Machine Intelligence and Learning Engine). Applying Apache Spark allows using MLlib, a machine learning algorithm library that can be accessed via Scala and Python. The GraphX library supports both graph data models and algorithm representations in the form of computations on graphs.
Today the core of Big Data technologies is formed by the Hadoop ecosystem. It is a whole set of software, utilities, database management systems using HDFS and Apache Hadoop.
There are plenty of options of the Hadoop setup. For a start, I would recommend using the CDH distribution kit (Cloudera Distribution Hadoop). On our projects, this option turned out to be the simplest and most stable to work with. There were numerous ecosystem program components, and we selected some of them that were the basis for a number of educational projects. It is Apache Hive – a data warehousing system for generalizing and analyzing data, as well as processing requests with the use of HiveQL, a language similar to SQL. The system focuses on operation with unstructured data by means of creating special storage structures. Apache Hbase, a non-relational DBMS, uses key-value tables and replaces the classical SQL for applying all features of the distributed file system in case of sparse data storage.
To collect data from a number of channels, the ecosystem contains a special tool called Flume, which you should become familiar with unless you are going to proceed with project development using the Internet of Things concept. In this case, it is necessary to pay attention to a separate platform for creating collections of data flows from millions of sources which uses a subscription to message topics, that is Apache Kafka.
I can’t but mention one more component of the Hadoop ecosystem – Apache ZooKeeper. It is designed to organize complex concurrent processes of storage, launch, and removal of apps in Apache Hadoop. At first, such a tool may seem unnecessary and too complicated, but if you participate in a Big Data project, ZooKeeper would be the right choice because standard technologies can`t provide high productivity.
To build high-performance data flow systems in real time it might be reasonable to exclude most of the Hadoop components and use a different platform, Apache Storm in particular. If a project focuses on analytics requiring complicated processing of large data, then you should deploy one more platform over Hadoop – Apache Spark oriented on large-scale computing procedures. All the above listed platforms can also be implemented in cloud services, therefore, they are available for research at low cost. Thus, you don`t need to deploy your own hardware cluster.
Below is a table containing all listed Big Data tools for the initial study: