Question Answering Systems. Challenge Accepted
As the team had extensive knowledge in Java software development and system integration, it was not difficult to grasp the basics of YodaQA. Its architecture is based on a pipeline created by IBM available now in Apache UIMA open source framework and on DKPro morphological parsers. An attempt just “to change the language” failed, as the morphological parsers applied in the project (StanfordParser, in particular) worked only with English-language models. Moreover, there were no East Slavic-language models, or the existing ones were non-operational.
Most importantly, the system architecture looked quite flexible, and the problem seemed to be easily solved: if we could not change the models, then we could try using different parsers and data structures.
The general system architecture looks as follows (based on the East Slavic-language examples):
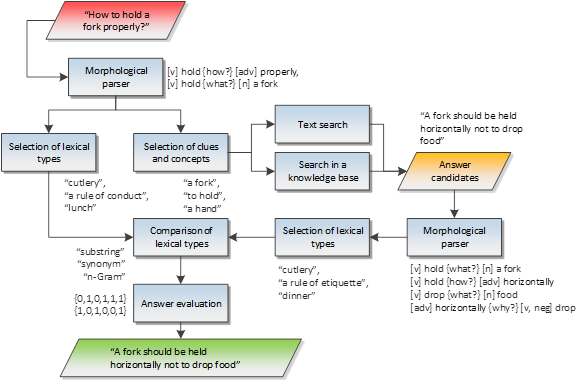
A morphological parser gets a question asked by a user, then it splits the text into a number of basic components (tokens) and defines relations between them. For example, the question “How to hold a fork properly?” is split into 4 tokens, the parts of speech are defined (to hold – a verb, a fork – a noun, etc.), and the relations are specified, for example, between “to hold” and “a fork”.
Then clues, concepts and lexical types are selected from the basic elements. Clues and concepts are keywords in the text that determine the content of the question or words that are generated from them based on the ontological relations in knowledge bases (for example, the clue “a hand” can be generated from “to hold” and “a fork”, as a fork is usually held by a hand). The sources of such relations are knowledge bases, DBpedia and Freebase in particular.
Lexical types are wide and descriptive notions; for example, “a fork” generates such types as “cutlery”, “material entity”, etc. The source of type checking is the YAGO knowledge base included into DBpedia datasets.
The received clues are forwarded to the search subsystem that can be structured (search in knowledge bases – DBpedia, Freebase) and unstructured (full-text search – Solr, Bing). The search results are similarly analyzed by a question to extract lexical types from them. The analysis method is identical to the question processing, except for a number of algorithms that deal with question words (what, when, how, etc.).
Next, the received set of lexical types from the question and answer candidates are compared among themselves based on a variety of algorithms (for example, inclusion of strings, synonymic, semantic and ontological relations), and then the matrix of comparison results is formed (strings – candidates for answers, columns – comparison algorithms). The sources of semantics are again knowledge bases.
The received matrix is forwarded to the assessment module which compares and evaluates the answers by means of machine learning. The answer with the maximum assessment score is considered to be correct (although the system provides a number of alternative answers indicating their relevance).
It was clear that in general it could run regardless of the language and knowledge domain, but some specific components (parsers, analyzers, extractors) had to be finalized or replaced.
The morphological parser turned out to be the main problem. Unfortunately, there was not a ready East Slavic-language-model for StanfordParser. Although there was an attempt to train it at Kazan State University, the results were either lost or the work was not accomplished. Therefore, we had to connect alternative parsers to the system, in particular, BreakIteratorSegmenter – for splitting sentences into tokens, TreePosTagger – for defining parts of speech, and MaltParser – for finding dependencies.
Basically, the replacement was fully functional, except for constituency parsing which had no equivalent, and the parsing results were presented in a slightly different data structure. As the subordinate system components used these structures directly, we had to change them as well.
The next problem was related to data sources. For structured data and ontological relations, the solution was quite clear – DBpedia contained everything we needed, and the part of data had tags in East Slavic languages. Therefore, it was sufficient to simply transfer search (SparQL requests) to tags of the other language or download and connect East Slavic-language datasets.
It should be noted that the transfer of DBpedia tags into East Slavic languages has not been completely performed, therefore the search results may contain names of entities, types, etc. both in East Slavic languages and English. We continued processing names in English, and, moreover, combined processing in two languages to increase a number of lexical types for the best comparison results.
Apache Solr is multilingual, and it supports full text search in East Slavic languages. The results sorted by relevance allow the system to analyze a limited set of texts that reduces response time of the system. The index format was developed, and all the required components for the improvement of the East Slavic-language search were connected. As a training material, we used a number of open encyclopedias for etiquette, based on which we developed extractors and converters in the right format to fill in an index.
Comparison of lexical types also had to be essentially worked over; in particular, it was transferred to lemmas of words instead of standard string comparison. To work with synonyms in East Slavic languages, the resources from the WordNet.ru base were used for which we developed a wrapper in Java. The semantic link search in DBpedia was also transferred to the data tags in East Slavic languages.
Other components were not changed essentially and were launched without any problems.
To be continued…
