Distributed Compilation of Projects Using Maven
Introduction
As it is stated in the introductory article “Flamenco Computational Cluster”, a developed computational cluster can be implemented as a parallel compilation of a Maven-built project. The current article describes theoretical and practical aspects of using the Flamenco computational cluster to solve the problem of parallel compilation of a Maven-built project. Moreover, we provide the use-cases of the plug-in Mavenoid.
Distributed Compilation of Projects Using Maven
One of the possible applications of the Flamenco computational cluster is distributed compilation of multi-module projects built by Apache Maven [2]. Let’s consider a Foo Project as an example. This project consists of 7 modules:
- parent (a parent project module operates project dependencies, plug-ins and contains the information about the version control system, etc.)
- internal-api (project internal API is used within an application for components interaction)
- api (external API is used to provide services for other applications)
- helpers (Helper classes, utilities)
- server (a module that handles external inquiries from users and software clients)
- client (a client that facilitates the integration of third-party applications with the external API)
- distribution (installation package)
The module dependency graph is presented below:
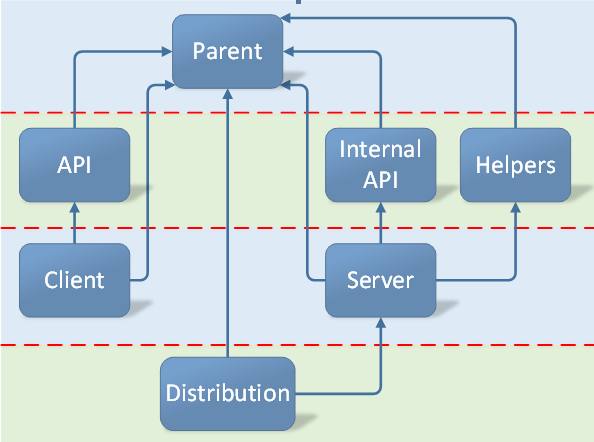
Fig.1: Typical project module dependencies.
In Figure 1 the arrow extending from one module to another indicates dependency of the first module on the second one. For example, all the modules depend on Parent (since they inherit it), Client depends on API, etc. Note that this graph is presented as a multilevel structure, the levels of which are divided by the red dashed lines.
The multilevel structure of the graph is vertices of the directed acyclic graph split into indexed subsets Vi, so if the directed edge goes from vertex v1∈Vj to vertex v2∈Vk, then j < k.
In general, on the Foo Project the relations are between modules on the same level (when j = k, but never less). Strictly speaking, the Foo Project can be presented as a directed acyclic graph split into indexed subsets, like the multilevel structure, but with vertices on the same level.
We always can regroup vertices placed at the same subset (j = k) to satisfy the strict inequality j < k. It follows from the graph’s acyclicity.
Each of sets Vi is the level of the multilevel structure, – its level number, the number of vertices |Vi| on the level is its width. The number of the levels in the multilevel structure is its height, whereas the maximum width of its levels is the width of the multilevel structure.
Roughly speaking, the wider and lower the structure is, the higher its parallelization potential is. For this project, the multilevel structure has height 4 and width 3. It practically means that no more than 3 modules of the project can be built simultaneously. First, Parent should be processed, then the modules API, Internal API and Helpers can be processed concurrently. As soon as these tasks are performed, the processing of Client, Server and then Distribution becomes possible.
Each node weight of the graph (setup time of the corresponding module) should also be taken into account. For the best parallelization, it is important that the setup time of various modules should be close. In other words, if one of the project modules takes 90% of the time, the maximum improvement that can be achieved (regardless of the form and structure of the multilevel structure) is equal to 10%. However, this requirement does not contradict a typical design of the application, and it is one of the reasons why overloaded modules should be divided into parts.
Amdahl’s law [1]:
Amdahl’s Law is presented in the following formula. However, Amdahl gave only a literal description, which was paraphrased by latecomers as follows:
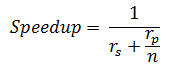
where rs+rp=1 and rs represents the ratio of the sequential portion in one program.
We can interpret this formula in the following way:
If a task is split into several parts, its total execution time on a parallel system cannot be less than the execution time of the longest fragment (provided that the speed of all the computing machines is the same).
Amdahl’s Law is one of the principal laws in the theory of parallel computing. Despite its simplicity, it has a number of quite interesting consequences. If applied to the project setup, it illustrates that the time of parallel compilation cannot be less than the compilation time of the longest chain in the graph extending from a vertex that doesn’t have any outgoing edges and a vertex that doesn’t have any entering edges. At the same time, the first vertex should be reachable from the second one.
The Mavenoid project
The Mavenoid project is a plug-in for Flamenco and a client that starts a compilation and controls its execution. The Mavenoid installer contains scripts the most useful of which will be considered below. Each of the scripts has a version under Windows and *nix (Linux, Unix, Minix and etc.) operating systems. In this article we assume that the user has set up the Mavenoid installer on the computer and added the bin folder to the PATH environment variable. The examples below are for Windows:
- mvnd.bat is the main script which allows compilation start-up. Its interface is similar to the mvn script which is a part of Maven. The main difference is that mvnd.bat doesn`t support all compilation options.
A start-up example:
mvnd -f /path/to/project/pom.xml -P distributions,integration-tests -DskipTests
- mpa.bat is the script that allows estimating the parallelization potential of the project, i.e. the theoretical limit which can be reached when using this approach.
A start-up example:
mpa -f /path/to/project/pom.xml -Pdistributions
Use-cases
As an example, we have taken the distributed compilation of the public “Alfresco” project. The project can be freely downloaded from the public repository at http://svn.alfresco.com/repos/alfresco-open-mirror/alfresco/HEAD.
We built a project using Maven in a standard way. To maintain the experimental integrity, this operation was performed twice because the first run loaded some lacking artifacts from the Internet that would impact on the general compilation time.
mvn clean install -DskipTests=true
The average compilation of the project on the computer takes 0:06:28, which is rather long lasting. We’ll consider this duration (0:06:28) the basic time of the project compilation. In each case we should decide how much time is reasonable and if we should improve the basic time. For the basic project compilation time we will compare it with the time of the alternative ways of compilation.
The second important indicator, which must be taken into account, is mpa. Assessment of acceleration of the project compilation is due to parallelization.
mpa pom.xml –skipTests
The average assessment has turned out to be 0:02:34 which corresponds to 60% of the time reduction against the basic compilation time.
Configuration of computing cluster for experiments
We will start with a slight node set-up and then install the flamenco.worker.pool.threads parameter in the conf/flamenco.properties file that is equal to 3. Thus, the maximum number of concurrent tasks on the node is defined.
…
#
# Local worker properties
#
# threads amount of worker’s thread pool to use for executing tasks
flamenco.worker.pool.threads=3
…
Start the Flamenco cluster node.
flamenco.bat install
flamenco.bat start
Experiments
Now it is possible to start the mvnd.sh script for the project compilation. As a rule, the first start-up takes some extra time for the “node warming-up”, the mavenoid plug-in loading and building of local repository pools.
As in the first case, we will repeat the project compilation to exclude the overhead of the first start-up.
Some attempts have been repeated and shown the average time 0:03:38 which is 44% faster than the basic compilation of the project.
Now we will try to increase the cluster power by adding one more node that physically is in the same subnet on a similar computer, and we will repeat these experiments.
The average compilation time has reached 0:03:09 and it is closer to MPA now. The gain has made up 51%.
The table with the experimental data is given below:
| Alfesco | ||||
| mpa | mvn | 1 node (3 thrd) | 2 node (3 thrd) | |
| 1 | 0:02:37 | 0:04:53 | 0:03:40 | 0:03:07 |
| 2 | 0:02:36 | 0:05:51 | 0:03:17 | 0:03:25 |
| 3 | 0:02:29 | 0:06:17 | 0:03:54 | 0:02:56 |
| 4 | 0:02:41 | 0:06:34 | 0:03:39 | 0:03:09 |
| 5 | 0:02:30 | 0:07:29 | 0:03:42 | 0:03:21 |
| 6 | 0:02:33 | 0:07:07 | 0:03:53 | 0:02:58 |
| 7 | 0:02:39 | 0:07:07 | 0:03:22 | 0:03:11 |
| AVG | 0:02:34 | 0:06:28 | 0:03:38 | 0:03:09 |
| RATE (*/mvn) |
0,399190581309787 | 1 | 0,561810154525386 | 0,48822663723326 |
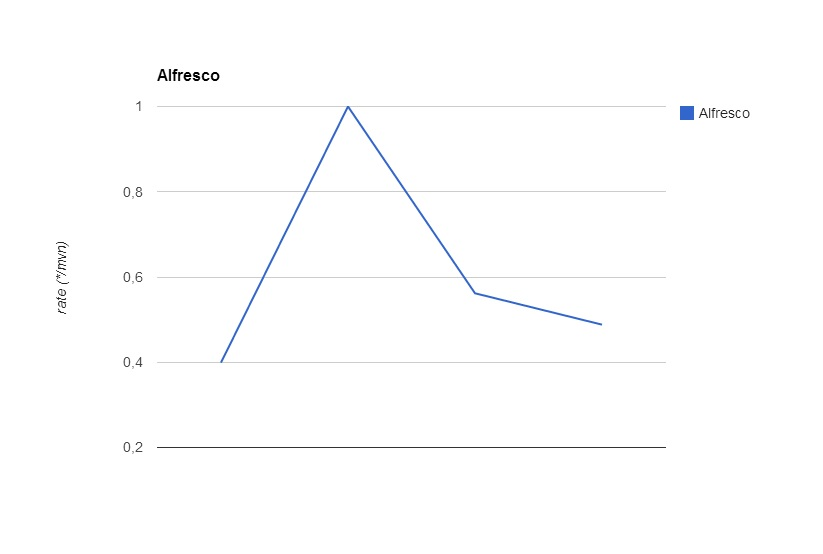
Fig. 2: Distribution of compilation time on the Alfresco project.
For comparison, let’s conduct similar experiments on another public project called “OpenGenesis“.
| Alfesco | ||||
| mpa | mvn | 1 node (3 thrd) | 2 node (3 thrd) | |
| 1 | 0:04:14 | 0:09:00 | 0:07:09 | 0:04:27 |
| 2 | 0:04:02 | 0:08:23 | 0:06:56 | 0:04:15 |
| 3 | 0:04:07 | 0:08:38 | 0:05:56 | 0:04:26 |
| 4 | 0:04:02 | 0:08:30 | 0:05:56 | 0:04:09 |
| 5 | 0:03:57 | 0:08:19 | 0:05:50 | 0:04:41 |
| 6 | 0:03:57 | 0:08:21 | 0:05:59 | 0:04:01 |
| 7 | 0:04:01 | 0:08:22 | 0:06:04 | 0:04:38 |
| AVG | 0:04:02 | 0:08:30 | 0:06:15 | 0:04:22 |
| RATE (*/mvn) |
0,47579065211307 | 1 | 0,736076126504338 | 0,5141337811363 |
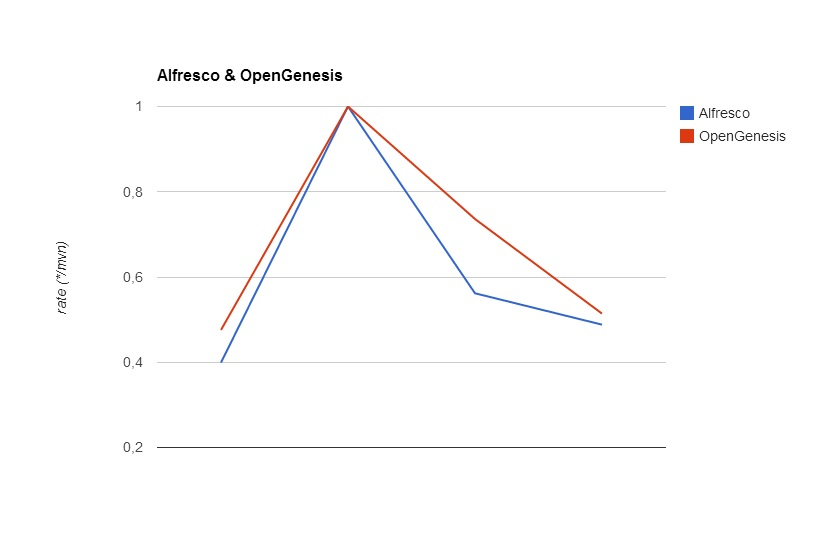
Fig. 4: Distribution of compilation time on the Alfresco and OpenGenesis projects.
The tendency remains on the OpenGenesis project, and the gain has made up 26,4% on one node and 48,6% on two nodes.
Conclusion
The article illustrates how to accelerate the compilation process of the projects using Maven. Also, the work of useful utilities for the assessment of distributed compiling potential of multi-module projects has been demonstrated, and practical examples have been given.
It is impossible to accelerate the project compilation continuously, as there are a number of restrictions on this from a practical point of view (overhead costs of data transmission on networks, imbalance of the project module sizes, excessive background loading of the processor on the nodes composing a cluster), as well as theoretical restrictions formulated in Amdahl’s law. Despite these restrictions, in practice the main part of the projects lies in the field where a noticeable performance improvement can be achieved up to 30-60%.
References
1. Amdahl, Gene M. (1967). Validity of the single processor approach to achieving large scale computing capabilities. IBM Sunnyvale, California. Retrieved October 23, 2014, from http://www-inst.eecs.berkeley.edu/~n252/paper/Amdahl.pdf
2. Apache Maven Project. (2014). Welcome to Apache Maven. Retrieved October 22, 2014, from http://maven.apache.org/
