Automation of Information System Engineering. The Solution
We continue talking about automation of the information system engineering. In the first part we introduced the challenge met by our development team. And now we would like to describe our solution.
We started with a deployment of a work environment. AXURE was deployed together with SVN for collaborative work. The EA model was implemented on the database server, domain users (SSO) were connected and got an option to edit the model simultaneously.
Everything was ready for the design but the model tree did not contain elements. We started with the creation of a view where we set the customer’s initial requirements listed in the source documentation.
To collect and process the specified requirements gathered during the automation object research, we created a separate folder in the model where we placed the specified requirements. We combined the specified and initial requirements that allowed us to manage the project frames and clearly understand which basic requirements were specified and which requirements were additional.
During the model design, we developed business processes in the BPMN notation and marked the points of process automation where the system would be used for data processing.
After the requirements were composed and preliminary data was collected, we created a domain model (a database logic structure). Screen form prototypes were built based on the domain model.
Next, we described the system functionality in detail and went through the functional packages. The functional packages contained images with screen forms prototypes, the required set of diagrams (describing state, activities, sequences), and the description of use cases. Use cases were described specifying limits (preconditions and postconditions for implementation) and performance scripts (direct, alternative, exceptional – as required).
To describe relations between model elements, we used traceability matrices and tables where elements of various types could be displayed in rows, and columns. This eliminated the need to generate a large number of diagrams, drag items and set relations between elements. Profiles could be saved, and it was easy to get to them when changing relations (setting relations for new elements).
We applied tracing of various types: components and functional packages, executives and working places (standard infrastructure), executives and functionality, functional packages and data source systems, initial requirements and specified requirements, specified requirements and functional packages, etc. Based on the same relations, and the same model elements, it was possible to generate various output representations, for example, functional packages and portals, functional packages and data sources that generated data displayed in a functional package.
The target design model is presented as follows:
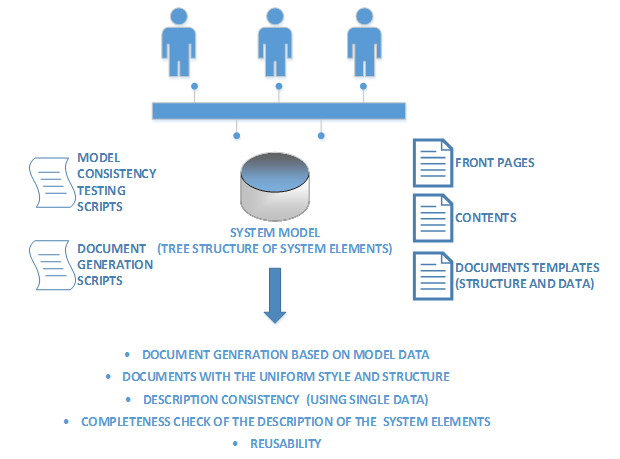
Next, we used model data for generation of the output documentation describing the system, but at first we checked whether all the relevant data was entered into the model and the description was full. For this purpose we developed a set of scripts to check completeness of the description of the system behavior. Scripts ran through the model tree structure and checked filling of data into the system elements as well as availability of the required relations between the system elements. Then a report on possible model remarks was created. Successful execution of scripts ensured that all necessary element data was completed.
For output documentation, we created templates for its generation. The templates were developed in the WYSIWYG mode for specifying element types (we used template sections) which had to be included in the document. Then we placed document attributes in the document using formatting, tables, and lists. We designed front pages of the project documents which were used at generation of documentation and contents (uniform for all project documentation). As for the templates, we used SQL sampling for output of elements of the appropriate type connected to the generated element.
We developed scripts for complex document generation, for data output on different types of elements, or output of relations on elements located in different model packages. Within the generation process, an element, the data on which had to be displayed, was forwarded to the generator entry, as well as a template which contained tagging and data for displaying.
We also used scripts for package generation of documentation (all functional packages with a definite status). Thus, names of document files could immediately show a version and status so that while viewing the folder a user could see at a glance what was ready and what had to be done.
Therefore, when the process of making changes to the model was stopped, and model elements (or packages) were marked with the appropriate statuses, we performed generation of all required documentation that contained actual names and descriptions of elements, uniform front pages, and a glossary.
The operation with the model within the documentation generation was similar to filling of analytical reports based on the transactional database. However, as the result we got a description of the system behavior in different views, and not figures.
It should be noted that after implementation of the first project, scripts and templates can be reused and, thus, significantly reduce labor costs in the subsequent projects realized with the use of automated design tools.
To be continued…
