Quickstart: Build an AI-Powered MVP in 7 Days
Ship an AI prototype in seven days without wasting months on engineering overhead. This playbook gives a day-by-day sprint plan with concrete deliverables, practical checklists, and the exact tradeoffs to make at each stage. It’s written for busy founders and PMs who want a fast, low-risk path to validate real user value from an AI feature — not an academic essay, but a bootstrapped production-oriented process you can run this week.
How to use this guide
Read the high-level sprint first, then use each day’s section as your checklist. If you’re a team of one, compress tasks and cut optional extras; if you have 2–4 people, assign roles (PM, ML/engineer, designer, QA) and follow the timeline.
Key constraints we optimize for:
-
Speed > perfection — deliver something testable in 7 days.
-
Value > novelty — validate a measurable customer outcome, not model accuracy alone.
-
Low blast radius — avoid risky actions (payments, PII writes) in the MVP.
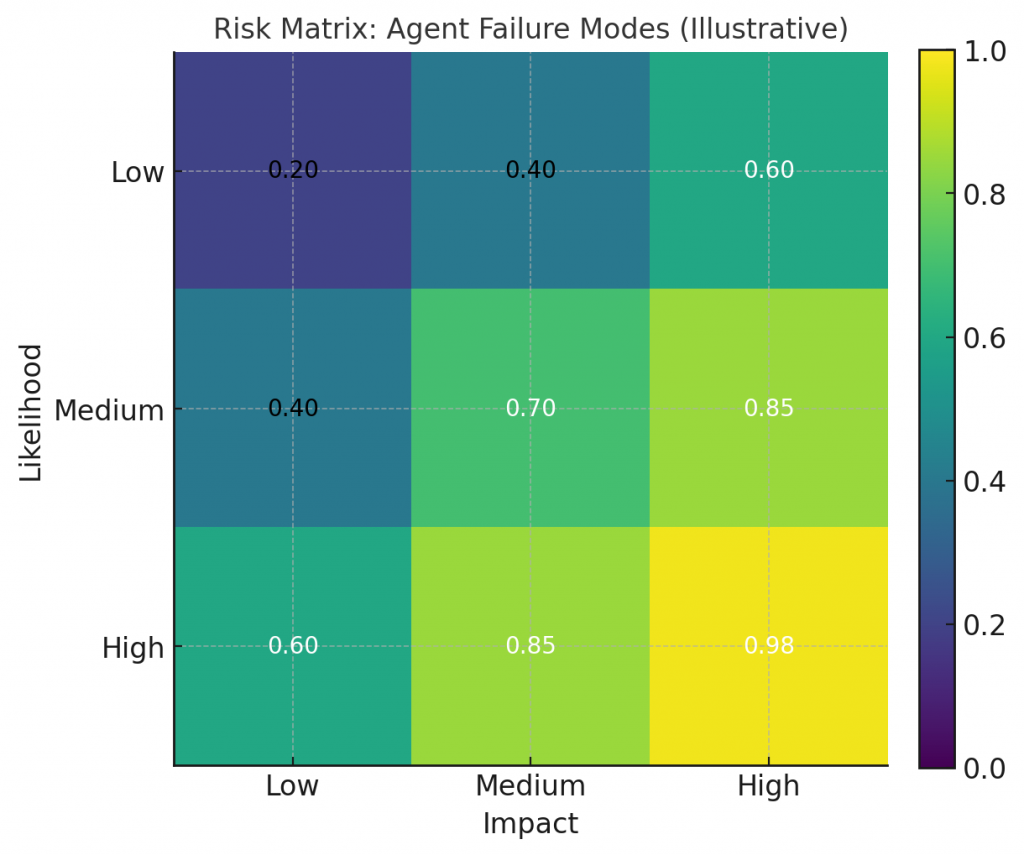
The 7-day high-level plan (quick view)
-
Day 0 (Prep / Scope): define the value hypothesis, success metrics, and minimal user journey. Final deliverable: one-page spec + sprint backlog.
-
Day 1 (Data & Inputs): audit and collect the smallest dataset that proves the product. Deliverable: dataset + labeling plan.
-
Day 2 (Prototype Build — Phase 1): wire up a minimal end-to-end flow using managed model APIs or no-code tools. Deliverable: clickable demo or API prototype.
-
Day 3 (Iterate & Integrate): add grounding/RAG or lightweight retrieval, implement small UX fixes. Deliverable: second-iteration prototype with evidence grounding.
-
Day 4 (Testing & Metrics): instrument metrics, run scenario tests and basic QA. Deliverable: telemetry dashboard + test log.
-
Day 5 (Pilot with Users): run a closed pilot (beta users or internal staff) and collect qualitative feedback. Deliverable: pilot results + annotated feedback.
-
Day 6 (Polish & Safety): add simple safety features, fallbacks, and human escalation. Deliverable: hardened MVP with guardrails.
-
Day 7 (Demo & Next Steps): deliverables for stakeholders: demo, decision report, roadmap. Deliverable: demo script, decision doc, and 30-/90-day plan.
Now we’ll walk through each day with practical steps, templates, and pitfalls to avoid.
Day 0 — Prep & Scope: lock the target (timebox: 3–4 hours)
Goal: Decide exactly what you will validate and what “done” looks like in 7 days.
Deliverable
One-page spec with:
-
Value hypothesis in one sentence.
-
Primary success metric (how you’ll know you succeeded).
-
Target user & minimal journey (user story).
-
Non-goals (what you won’t do).
-
Team roster and daily commitments.
Steps
-
Write a clear value hypothesis.
Format: “If we provide [AI feature] to [user], then [benefit] will increase by [metric] within [timeframe].”
Example: “If we add an AI answer assistant to our billing portal, then support ticket deflection will increase by 20% over two weeks.” -
Pick one measurable metric.
Avoid vague goals. Examples: conversation containment rate, conversion lift, minutes saved per user, number of qualified leads per session. -
Define the minimal user flow.
Sketch the exact happy path and one critical edge case. For example: “User uploads doc → AI extracts three fields → user confirms → system acknowledges.” Keep it to 3–5 UIs/actions. -
Decide constraints & safety rules.
Will the bot ever take irreversible actions? If yes, require human approval. For MVP, avoid auto-execution of sensitive operations. -
Assemble your team and calendar.
Assign roles: PM (owner), engineer/ML, designer, QA/tester. Block 1–2 hours/day for review sessions. -
Create a sprint backlog.
List exact tasks for each day and mark “must have” vs “nice to have.”
Pitfalls to avoid
-
Trying to validate multiple hypotheses at once. One metric = clarity.
-
Choosing a KPI that’s too slow to measure (e.g., retention over months). Pick short-cycle metrics.
Day 1 — Data & Inputs: gather the minimum viable data (timebox: 6–8 hours)
Goal: Acquire a dataset sufficient to run a working prototype and evaluate it qualitatively.
Deliverable
-
Working dataset (CSV/JSON) or synthetic mapping.
-
Labeling instructions and at least 50–200 labeled examples (depending on scope).
-
Data provenance notes.
Steps
-
Audit what you already have.
Look for internal logs, transcripts, spreadsheets, or product outputs you can use immediately. Reuse beats recreate. -
Define the minimal input schema.
What fields does your model need? e.g., user text + metadata (user type, product id) + optional attachments. -
Collect a small seed set (50–200 examples).
For a chatbot or extraction task, 200 examples can give useful signals. For complex classification, you may need more—start with what’s feasible. -
Label quickly and cheaply.
-
Do it yourself or use internal staff for quality.
-
If budget allows, use a microtasking service for low cost.
-
Make label instructions prescriptive and short.
-
-
Synthesize data if necessary.
If no real data exists, create synthetic examples that exercise the happy path and typical edge-cases. Use them to iterate UX and prompt design. -
Sanitize and document provenance.
Remove PII if you can; record where each example came from and when.
Pitfalls to avoid
-
Spending days to get “perfect” labeled data. The MVP needs representative—not exhaustive—data.
-
Forgetting to log provenance (hard to debug later).
Day 2 — Prototype Build (Phase 1): get an end-to-end demo (timebox: full day)
Goal: Deliver a minimally functional pipeline that demonstrates the value hypothesis using managed APIs or no-code tools.
Deliverable
A working prototype you can demo end-to-end (even if it’s a demo script manipulating backend steps). Could be a web UI, chatbot, or an internal script.
Strategy choices (pick one)
-
No-code / low-code builder: Use a visual bot builder or platform (great for chatbots). Pros: fastest. Cons: vendor limitations.
-
Managed model APIs: Use an LLM API (OpenAI, Anthropic, etc.) for the “brain” and your lightweight server for glue logic. Pros: flexible, quick. Cons: cost.
-
Local libs + small model: If privacy or cost constraints exist, run a local small-model stack—but this takes more infra.
For 7-day MVP, use a managed model unless you have strong reasons not to.
Steps
-
Wire the input → model → output flow.
Implement the simplest mapping: user input → prompt(template) → model response → present to user. -
Hardcode nonessential integrations.
If you would normally call a CRM, instead stub a fake response with realistic data for the demo. -
Design minimal UX that shows confidence & provenance.
For example: show the source documents, highlight extracted fields, or show “why the agent replied” notes. -
Keep prompts simple & deterministic.
Use templates with placeholders. Example: -
Instrument a manual metric logger.
Save user interactions and outcomes in a spreadsheet or small DB so you can analyze pilot data. -
Create a demo script.
Prepare a few typical flows (happy path + two edge cases) to show stakeholders.
Developer tips
-
Start with synchronous requests and short timeouts.
-
Add basic input validation on the client side.
-
Treat model outputs as untrusted — parse and validate them.
Pitfalls to avoid
-
Building full auth, billing, and integrations at this stage — skip until validated.
-
Relying purely on “happy path” examples; include at least one messy example in your demo.
Day 3 — Add grounding & improve accuracy (timebox: full day)
Goal: Reduce hallucinations and improve trust by grounding outputs with retrieval or deterministic modules.
Deliverable
Prototype with retrieval (RAG) or rule-based verification integrated. If not applicable, strengthen prompt engineering and add simple checks.
Steps
-
If factuality matters, add retrieval.
-
Build a tiny retrieval index (local JSON or vector DB) of the documents you want to ground against.
-
Precompute embeddings if using a vector DB. For speed, a simple keyword search over indexed docs is fine for MVP.
-
-
Add a verification pass.
After the model returns a result, run a deterministic check: does the extracted invoice number match a regex? Is the total numeric and in a valid range? If checks fail, ask for clarification or route to human review. -
Add prompt context: show supporting evidence.
Modify the prompt to ask the model to cite the paragraph or sentence it used to produce a fact. Then surface that citation to the user. -
Iterate prompts and keep a prompt library.
Keep versions and test them with your seed examples. Save the exact prompt text for provenance. -
Tweak UX for uncertainty.
Show “confidence” indicators (low/medium/high) based on heuristics (regex pass + retrieval score + model token probabilities if available).
Example flow with RAG (simple)
-
User query → retrieve up to 3 documents by keyword or vector similarity → send documents + query to model → model returns answer + citations → UI shows answer and links to cited docs.
Pitfalls to avoid
-
Over-indexing vast corpora; keep the RAG index small and relevant for the MVP.
-
Mixing too many retrieval sources — one small index is easier to manage.
Day 4 — Testing, Instrumentation & Baseline Metrics (timebox: full day)
Goal: Validate the prototype works across intended scenarios; define and begin collecting the primary metric(s).
Deliverable
-
Test suite (manual + automated scenarios).
-
Telemetry dashboard (even a spreadsheet counts).
-
Baseline metric snapshot.
Steps
-
Define test cases.
Cover: happy path, three realistic edge cases, and at least one adversarial example. For each case, record expected outputs. -
Run scenario tests with your seed dataset. Capture model outputs and the pass/fail status against your expected answers. Store these results.
-
Automate one smoke test.
Use a small script or CI job that runs the happy path and fails if output deviates beyond tolerance. -
Set up basic telemetry.
Track:-
Number of demos/pilot runs.
-
Containment or correctness rate on labeled samples.
-
Latency (model response time).
-
Cost per call (if using billed API).
Start with a Google Sheet or Airtable if you lack observability infra. Document collection timestamps and model versions.
-
-
Define your success threshold.
Example: “If 70% of pilot users can complete the task without human help and the average task time drops by 30%, we proceed.” Pick a numerical value. -
Log every prompt and response for postmortem.
Keep a simple JSON log: prompt, model response, timestamp, user id (if any), and any verification flags.
Pitfalls to avoid
-
Ignoring cost metrics. LLM calls add up quickly—track them from day 1.
-
Not automating even minimal smoke tests — human testing is slow and error-prone.
Day 5 — Pilot with Real Users (timebox: full day + ongoing)
Goal: Get real user feedback from a small set of target users or internal stakeholders.
Deliverable
Pilot report: quantitative metrics + qualitative notes with prioritized fixes.
Steps
-
Recruit your pilot group.
Aim for 5–20 users: a mix of power users and naive users. Internal staff can be fine if external users aren’t available. -
Define pilot instructions and incentives.
Provide a one-page how-to and a short survey (3 questions + optional comments). Offer credit or a small gift for participation. -
Run the pilot sessions.
Observe at least some live sessions. Encourage users to “think aloud” or record sessions (with consent). Collect examples that break the system. -
Collect metrics and feedback.
-
Completion rate.
-
Time-to-complete tasks.
-
Satisfaction (1–5) and NPS if appropriate.
-
Showstopper notes: where the agent failed.
-
-
Triage issues immediately.
Classify pilot feedback into: showstopper, high priority, nice-to-have, and UX. Implement or schedule fixes for showstoppers before wider exposure. -
Document case studies.
Capture 2–3 short user stories that show the value (before → after).
Pitfalls to avoid
-
Asking for too much feedback. Keep surveys short and focused.
-
Running pilot without clear consent for logging prompts and outputs—be transparent.

Day 6 — Hardening & Safety: add guardrails (timebox: full day)
Goal: Add simple, practical safety measures and failover behavior so the prototype can survive more users.
Deliverable
A hardened MVP with basic guardrails, fallback UX, and a human escalation flow.
Safety features to add (pick the most relevant)
-
Human approval gate for any irreversible or costly action. If an action crosses a threshold, require a reviewer confirm it.
-
Sanitization & redaction: remove or mask PII from displayed outputs and logs.
-
Rate limits & quotas: prevent runaway model calls from a misbehaving user.
-
Fallback & default messages: when the agent is unsure, respond with a trusted fallback like “I’m not sure — I’ll flag this to a specialist.”
-
Prompt injection defenses: treat user-provided text carefully when concatenating to prompts; do not allow free passage of control tokens or instructions.
-
Logging & retention policy: decide retention windows for stored prompts and delete PII when no longer needed.
UX considerations
-
Make uncertainty visible: don’t present hallucinations as facts.
-
Provide an “ask a human” button and show provenance for model assertions.
Operational steps
-
Create a simple incident playbook: how to revoke access, rollback changes, and notify users if something goes wrong.
-
Assign an on-call person during the pilot period.
Pitfalls to avoid
-
Overengineering safety — keep it commensurate with the MVP risk profile.
-
Forgetting to test the fail paths: simulate model outages and network errors.
Day 7 — Demo, Decision & Next Steps (timebox: half day – full day)
Goal: Present the MVP, decide whether to iterate, scale, or kill the idea.
Deliverable
-
Live demo & recording.
-
One-page decision memo: metric results, user quotes, cost estimate, proposed roadmap (30/90/180 days).
-
A prioritized backlog for next steps.
Steps
-
Run the demo for stakeholders.
Show the happy path, one edge case, and one failure/recovery scenario. Use real pilot data to tell the story. -
Deliver the metrics snapshot.
Present the primary metric, cost per run, containment/accuracy, and user satisfaction. Show whether you met the success threshold. -
Make a recommendation.
Options:-
Kill — evidence shows no value; capture learnings.
-
Iterate — fix key issues and run another pilot (common).
-
Scale — invest in production hardening and integration (if metric thresholds and risk profile are met).
-
-
Write the 30-/90-day plan for the chosen path: people to hire, infra to build, and compliance tasks.
-
Prepare a handoff package for engineering/ops if moving to production: dataset, prompt versions, logs, test suite, and runbook.
Pitfalls to avoid
-
Decision paralysis — make a clear call with data.
-
Ignoring cost implications of scaling: model spend and vector DB costs can balloon.
Post-MVP: common next steps if you decide to scale
If the data shows value, the work ahead typically includes:
-
Integrate with production systems. Replace stubs with real connectors and secure credentials.
-
Build a proper retrieval / RAG infra. Move from local JSON to a scalable vector DB with versioning.
-
Automate CI for scenario testing. Run automated scenario suites on every change.
-
Add governance & audit tooling. Prompt/response archive with retention and export capabilities.
-
Optimize costs. Implement tiered models, caching, and batching flows.
-
Security & compliance audits. Formal review for PII handling, vendor contracts, and legal obligations.
-
Scale UX & monitoring. Add dashboards, SLOs, and runbooks for incidents.
Tooling cheat sheet (fast, practical options)
These are examples of fast tools and patterns that help you ship quickly:
-
Model APIs: managed LLMs for rapid iteration. (Use the vendor you already have credits with.)
-
RAG basics: small vector store (FAISS or lightweight hosted option) or even simple keyword search for MVP.
-
No-code chat builders: useful if your product is a conversational interface.
-
Logging & telemetry: Google Sheets / Airtable for day-one metrics; upgrade to Postgres + Grafana for more.
-
CI & smoke tests: GitHub Actions for scheduled scenario runs.
-
Secrets: Vault or platform secrets for short access. For MVP, use encrypted env vars but plan to migrate.
-
Sandbox execution: containerized microservice with limited privileges (if executing code or actions).
Measurement: what to track (practical KPIs)
Pick 3–5 KPIs tied to your value hypothesis:
-
Primary KPI (outcome): e.g., % tasks completed without human help (containment), conversion lift, time saved.
-
Quality KPI: accuracy or precision of domain outputs on labeled sample.
-
Cost KPI: cost per completed task (model + infra).
-
Adoption KPI: active users in pilot or sessions/day.
-
Safety KPI: rate of fallbacks to human, number of hallucinations per 100 runs.
Track these daily during the pilot.
Communication templates (tiny, copy-paste friendly)
Pilot invite email (short):
Hi [Name],
We’re testing a new AI feature that helps [what it does]. Would you try it for 10 minutes and share feedback? Reply here and I’ll send the link. Thanks! — [PM name]
Bug report format (one line + priority):
[User ID] — [scenario] — expected [x], saw [y] — priority [low/med/high]
Demo script outline (3 parts):
-
Problem statement + metric.
-
Live happy path.
-
Edge case + human escalation + cost snapshot.
-
Ask / recommendation.
Risks & mitigation summary (executive view)
-
Risk: Hallucination → Mitigation: RAG grounding + verifier rules + human gate.
-
Risk: Cost explosion → Mitigation: monitor token usage, tiered models, cache common queries.
-
Risk: Privacy leakage → Mitigation: PII redaction, short retention, vendor contract checks.
-
Risk: Reputational error (public answer wrong) → Mitigation: label outputs as “suggested” + human oversight for public publish.
-
Risk: Vendor lock-in → Mitigation: abstract model calls behind a thin adapter layer.
Example 7-day sprint: concrete timeline (sample team of 3)
Team: PM (you), Engineer (1), Designer (0.5 part time).
-
Day 0 (Mon morning): 2-hour kickoff, spec & backlog.
-
Day 1 (Mon afternoon – Tue): engineer pulls dataset, PM writes labeling guide. Designer drafts minimal UI.
-
Day 2 (Tue afternoon – Wed): engineer wires model API and simple UI. Demo end-to-end.
-
Day 3 (Wed): retrieval added; prompt tuning.
-
Day 4 (Thu): test runs, telemetry wired, sample smoke tests.
-
Day 5 (Fri): pilot with 8 users, collect feedback.
-
Day 6 (Sat): fix critical issues, add human gate.
-
Day 7 (Sun/Monday): demo + decision.
Adapt to your calendar—this plan assumes focused, blocked time.
Realistic expectations & why this works
A one-week MVP is not a final product — it’s a rapid experiment to test a focused hypothesis. You will not ship a fully hardened, globally scalable system in seven days. What you will accomplish is far more valuable: a tested hypothesis, concrete user feedback, cost signals and a data-driven decision on whether to invest. That’s what product discovery is about.
