AI Agents in Production: A Practical Playbook for Engineering Teams
Agentic AI—software that accepts a goal, breaks it down into steps, calls tools and services, and iterates until completion—is moving from research demos into real products. To adopt agents safely in production you must design clear orchestration, enforce strong observability and provenance, apply strict security and governance controls, and treat agent runs like any other critical service. This guide gives a pragmatic roadmap for building, testing, deploying, and operating agentic workflows at scale.
1. What we mean by “AI agents” and why they’re different
When people say “AI agent” they usually mean a system that:
-
takes a high-level objective from a person or another system;
-
decomposes that objective into subtasks (planning);
-
invokes models, databases, or external APIs as tools to accomplish those subtasks; and
-
monitors outcomes, retries, or escalates when needed.
That chain of planning → tooling → execution distinguishes agents from single-turn LLM calls. Agents operate across time and systems, often retaining state, using retrieval to ground decisions, and performing actions that affect downstream systems. That additional capability is powerful but it also multiplies operational, security, and compliance complexity.
2. Why now? The shift from prompts to production
Several trends have pushed agentic systems into practical territory: models with better chain-of-thought and planning capabilities; vendor SDKs and orchestration primitives; improved retrieval and grounding techniques; and an expanding ecosystem of connectors to databases, document stores and APIs. Together, these make it feasible to build multi-step automations that can actually finish complex tasks end-to-end—if you treat them as software systems, not toys.
3. Business cases where agents add real value
Agentic workflows are especially useful when tasks are multi-step, require cross-system coordination, or need adaptive decision-making. Typical production use cases include:
-
Document research & summarization: sweep multiple sources, extract facts, and synthesize structured reports.
-
Customer workflows: orchestrate onboarding, billing, provisioning and notifications across services.
-
Automated ops assistants: triage incidents, gather diagnostics and prepare incident tickets for humans.
-
Finance operations: process invoices, validate against POs, route exceptions.
-
Personal productivity: multi-app agents that schedule, triage email, and prepare summaries.
Pick early targets that have high value but low blast radius—internal tooling, non-critical automation, or data-synthesis tasks.
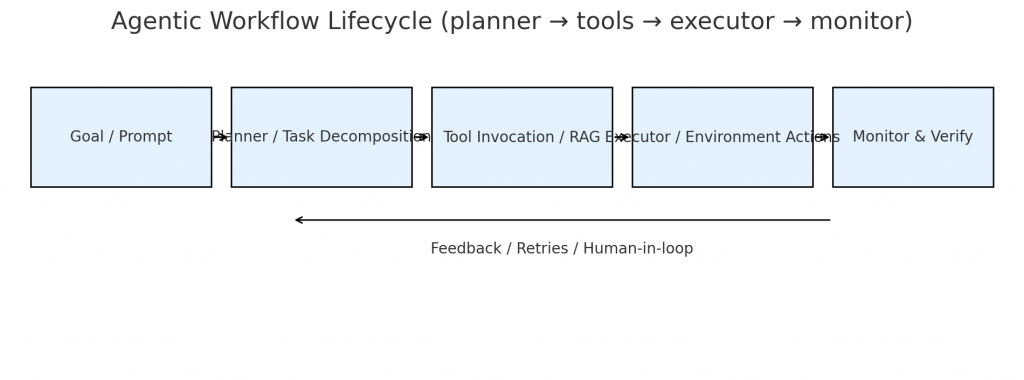
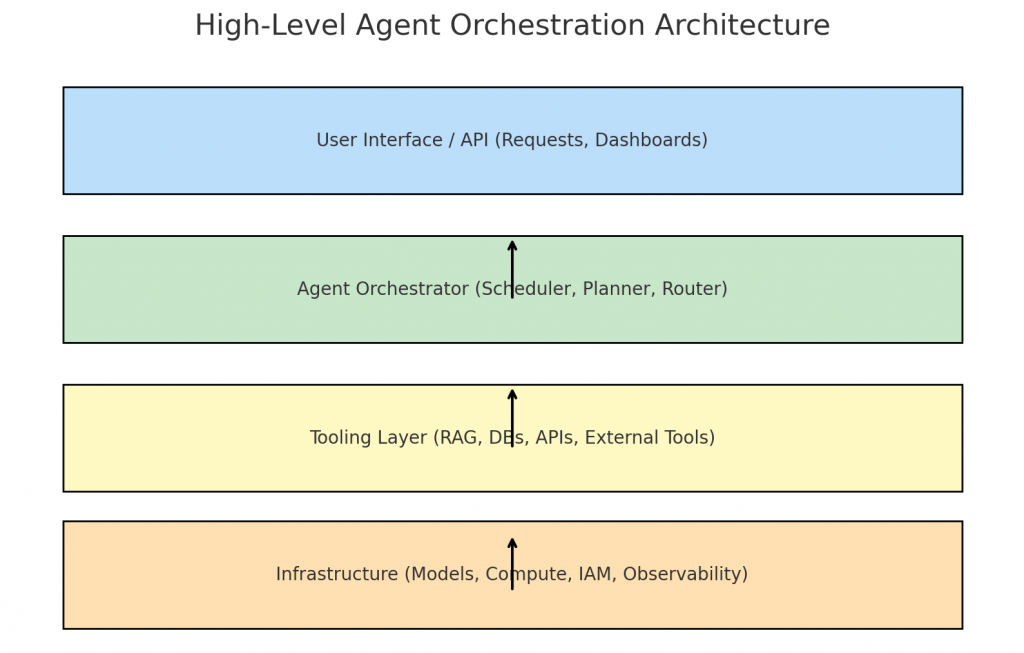
4. Core architecture: planner → tools → executor → verifier
A practical, production-ready agent architecture separates responsibilities:
-
Goal intake & request layer — receives user intent and metadata (who requested, authorization scope).
-
Planner/Decomposer — decides the steps needed to meet the goal; may be model-driven.
-
Tool layer / Invokers — adapters that perform concrete actions (DB queries, API calls, snippets of code, retrieval). These are deterministic, instrumented, and sandboxed.
-
Executor / Orchestrator — schedules subtasks, manages retries, concurrency and resource budgets.
-
Verifier & Monitor — validates outputs against rules, runs verification tests, and triggers human review if confidence is low.
-
State & Provenance store — durable, auditable logs of prompts, model versions, retrieved documents, tool outputs and final actions.
Separate these concerns so each piece can be tested, instrumented and hardened independently.
5. Choosing how to orchestrate: buy, assemble, or build
-
Buy managed agent platforms for speed. Pros: fast prototyping, built-in safety features. Cons: vendor lock-in, limited control over model/data residency.
-
Assemble with open frameworks (e.g., orchestration libs) to balance flexibility and speed. Pros: modular connectors, ecosystem support. Cons: still work to integrate observability and governance.
-
Build a custom orchestrator when you need unique policies, heavy compliance or special performance characteristics. Only do this if you have the skills and resources to implement the operational controls you’ll need.
A common pattern: prototype with an SDK, then reimplement the orchestrator components you depend on if/when you scale or need stricter control.
6. Hard testing requirements for agentic systems
Agentic workflows need a more sophisticated test strategy than typical apps:
-
Unit tests for deterministic components (adapters, parsers, validators).
-
Contract tests to ensure tool outputs conform to schemas and tolerances.
-
Scenario-based integration tests where you mock tool responses and test full plan execution across steps.
-
Regression harnesses that replay stored prompts, retrieval docs and tool outcomes to detect behavior drift.
-
Adversarial testing and chaos experiments: malformed inputs, latency and partial failures to ensure graceful degradation.
-
Human acceptance tests for high-risk decision paths.
Automate these in CI; fail builds on critical regressions. Use golden output approaches with allowed variability for model-driven outputs.
7. Observability and provenance — what you must collect
Visibility is non-negotiable. At minimum, capture:
-
Exact prompt text and model metadata (name, version, parameters).
-
Retrieval payload IDs and timestamps so you can reproduce grounding context.
-
Tool call logs with inputs, responses, latencies and errors.
-
State snapshots for long-running runs (intermediate results).
-
Action audit trail: who/what authorized actions, timestamps, and outputs.
-
Cost telemetry: tokens, compute, API charges per run.
Make these accessible in dashboards and searchable for debugging and audits.
8. Security controls & safe execution
Agentic systems interact with credentials, PII, and production systems—so apply bar-level security:
-
Least-privilege connectors. Issue narrow-scoped, short-lived credentials for tool calls and rotate automatically.
-
Sandboxed execution. Run any code or external actions in restricted, network-limited sandboxes with resource caps.
-
Input cleansing & safe coding patterns. Enforce parameterized queries; never accept generated code as-is without review.
-
Secrets redaction. Prevent agents from logging secrets or returning sensitive tokens in outputs.
-
Approval gates. Set mandatory human approval for money movement, infra changes, user access changes.
-
Dependency scanning & SBOMs. If an agent suggests third-party libs, verify before use; emit SBOMs for every deployment.
-
Rate limits & circuit breakers. Limit the frequency and blast radius of tool calls and model usage.
Treat agent runs as you would any privileged automation process.
9. Governance & compliance considerations
Operationalize governance early:
-
Provenance retention policy. Keep prompts, retrieval docs, and tool outputs long enough for audits, but comply with data retention laws.
-
Vendor contracts must specify data handling, retention and liability boundaries.
-
Defined scope of autonomy. Use a whitelist/blacklist for tasks agents can execute without human oversight.
-
Audit & review boards. Cross-functional review (security, legal, compliance, product) for high-risk agent features.
-
Red team exercises to probe prompt injection and adversarial behaviors.
If you operate under regional data laws, carefully manage model hosting and data egress.
10. Reliability and SRE practices
Agents require SRE discipline:
-
Feature flags to toggle agent capabilities per user group.
-
Canary rollouts (1% → 5% → 20% → 100%) with automated metrics checks.
-
Graceful fallbacks to human workflows or well-tested legacy handlers if the agent fails.
-
Queueing for long jobs: use durable workflows for tasks that exceed typical request latencies.
-
Incident runbooks for unintended agent actions, including how to revoke credentials and roll back side-effects.
Define metrics: containment rate (automation success without human help), time-to-resolution, false-positive rate and cost per completed task.
11. Cost control & economics
Agents are resource-intensive. Control spend by design:
-
Use cheaper models for routine tasks and reserve larger, costlier models for planning or complex reasoning.
-
Cache deterministic outputs from retrieval and model calls when safe.
-
Batch external calls where possible to reduce egress and per-call overhead.
-
Measure cost per successful task and use that as a KPI for optimization.
Visibility into cost helps justify business value and prevents runaway bills.
12. Human-in-the-loop patterns (practical)
Humans remain essential for safety and accountability:
-
Verify-only flows. Agent proposes; human approves. Best for high-stakes actions.
-
Confidence-based routing. Use model confidence and verifier checks to route low-confidence outcomes to humans.
-
Reviewer feedback loop. Capture corrections from humans and feed them into training cycles or prompt improvements.
-
Escalation rules. Define thresholds for immediate human attention (cost > X, PII involved, regulatory actions).
Design human workflows to be fast and contextual: include the agent’s reasoning, retrieval evidence and suggested action in the reviewer UI.
13. Common failure modes and how to mitigate them
-
Hallucinations. Ground every factual claim with retrieval and require verifiers for actions that modify state.
-
Credential leakage. Strip secrets from outputs, and never include raw credentials in logs shown to users.
-
Tool faults. Implement retries with exponential backoff and fallbacks to read-only modes.
-
Drift. Periodically re-evaluate retrieval indices and model behavior; automate data freshness checks.
-
Scale-related latency. Autoscale model fleets, or degrade gracefully by switching to a simpler handler.
Prioritize mitigations by potential impact.
14. A concrete safe workflow (invoice processing example)
Objective: validate an invoice against a PO and prepare approval if matched.
-
Intake: upload invoice to object storage; trigger agent with metadata (vendor, amount).
-
Extract: deterministic OCR pipeline extracts line items (no model hallucination on extraction).
-
Planner: agent checks extracted fields, queries PO DB via the tool adapter and computes variances.
-
Verifier: if variance < threshold, create staging invoice; if > threshold, route to human.
-
Approval: human reviewer sees all provenance (source documents, tool outputs, calculated differences) and approves.
-
Execution: on approval, agent schedules payment through a sandboxed executor that records the action and requires second signature for high amounts.
Safety points: never allow unattended payments above thresholds; all DB writes occur in staging with an audit trail.
15. Adoption roadmap (90-day tactical plan)
Phase 1 (week 1–3): select 1–2 low-risk pilots (internal ops, document summarization). Build a minimal orchestrator and ensure basic logging.
Phase 2 (week 4–8): implement CI tests, provenance capture, and a simple verifier. Roll out to a small group of users.
Phase 3 (week 9–12): add RBAC, secrets handling, sandboxed executors, and canary deployments. Measure containment, correctness and costs, and iterate.
Continue with scaling, governance formalization and red-team testing after initial success.
16. Teaming and cultural shifts
Agentic systems change how teams work. Prepare by:
-
Teaching engineers “prompt hygiene” and grounding patterns.
-
Creating a small, multi-disciplinary agent review board (product, security, legal, platform).
-
Treating prompts and agent configs as first-class artifacts under version control.
-
Incentivizing concise, testable agent behavior and reward safe rollouts.
17. Build vs buy: practical decision rules
-
Buy if you need speed to market and can accept vendor constraints.
-
Build if you need strict data residency, custom orchestration or must meet heavy compliance demands.
-
Hybrid: prototype on managed platforms; migrate orchestrator or critical connectors in-house at scale.
Plan migrations carefully; keep adapters stable to minimize rewrite.
18. Metrics to track (operational & business)
-
Containment rate: % tasks completed without human intervention.
-
Approval latency: average time human reviewers take for gated actions.
-
Accuracy/Precision for domain-specific outputs, measured against gold standards.
-
Cost per task including model and tool expense.
-
Failure rate & mean time to remediation.
-
User satisfaction where applicable (NPS, CSAT).
These help you balance automation ROI with risk.
19. Final recommendations
-
Start small and low-risk. Validate value before widening scope.
-
Log everything necessary to reproduce a run: prompts, retrieval docs, tool outputs and model metadata.
-
Build verification layers—not just better prompts. Use RAG, schema checks and human review.
-
Automate safety (CI, SAST, SBOM) but retain humans for high-impact decisions.
-
Treat agents as critical infrastructure: observability, runbooks and incident processes are essential.
Agents can multiply productivity—but only if engineered, governed and operated with the same rigor you would apply to any system that has the power to change your production state or user data.
