How AI Can Be Integrated into Electronic Health Record (EHR) Software
Artificial intelligence (AI) is no longer an optional experiment for health IT teams — it’s a practical capability that can make Electronic Health Records (EHRs) smarter, safer, and far more useful for clinicians, administrators, and patients. But integrating AI into EHR software is not just a matter of “dropping a model into the system.” It requires careful thinking about data pipelines, clinical workflows, governance, validation, security, and human factors.
This article is a hands-on guide for product managers, engineers, clinical informaticists, and health system leaders who want to integrate AI into EHR systems responsibly and effectively. You’ll find concrete patterns, architecture blueprints, implementation steps, evaluation metrics, deployment options, and a practical rollout roadmap.
Executive summary (the short version)
-
Goal: Use AI to augment clinical decision-making, automate routine tasks, reduce clinician burden, and improve outcomes — without disrupting workflows or compromising privacy.
-
Primary integration points: clinical documentation, decision support, imaging & pathology results, predictive analytics (risk scores), operational automation (scheduling, coding), and patient engagement.
-
Core requirements: high-quality data, real-time (or near-real-time) pipelines, MLOps and model governance, explainability, clinical validation, HIPAA-compliant security, and clinician-centric UI/UX.
-
Deployment modes: on-premises, cloud, hybrid, and federated learning; choose based on latency, privacy, regulatory, and operational constraints.
-
Rollout: small, measurable pilots → iterate with clinicians → scale with monitoring and governance.
Why integrate AI into EHRs? — key value propositions
-
Reduce clinician administrative burden
-
Automate clinical note generation from voice or structured data (assistive documentation; draft notes).
-
Auto-populate problem lists, order sets, and billing codes.
-
-
Improve diagnostic accuracy and triage
-
Highlight abnormal labs or imaging findings and surface differential diagnoses based on multimodal data.
-
Prioritize patients at high risk for deterioration so clinicians act earlier.
-
-
Personalize care
-
Suggest tailored medication dosing, contraindications, and follow-up intervals based on comorbidities and genomics.
-
Identify patients eligible for specific clinical trials.
-
-
Increase operational efficiency
-
Optimize bed management, staffing, and clinic schedules.
-
Improve revenue cycle by identifying missed charges and coding opportunities.
-
-
Enhance patient engagement
-
Generate tailored education, triage via chatbots, and manage remote monitoring alerting.
-
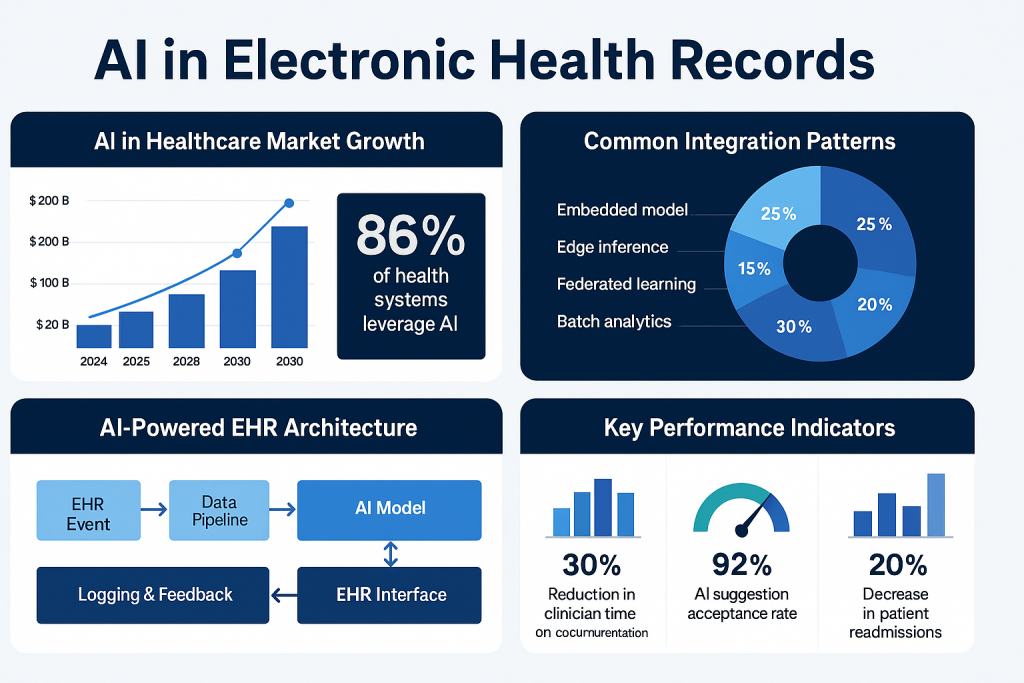
High-level integration patterns
Before design or coding, pick one or more integration patterns depending on the use case and constraints.
-
Embedded model (in-EHR microservice)
-
AI runs as a microservice tightly coupled with the EHR backend. Low latency, easy to trigger from EHR actions (e.g., on lab result arrival). Good for decision support where speed is critical.
-
Pros: fast response time, controlled environment, easier to meet audit/logging requirements.
-
Cons: infrastructure burden on hospital IT; scaling models for multiple sites can be harder.
-
-
External inference service (API / cloud)
-
EHR calls an external API hosted by cloud provider or vendor. Useful for heavy compute tasks (imaging analysis, genomics).
-
Pros: scalable, simpler model updates, leverages managed ML infrastructure.
-
Cons: data privacy considerations, network latency, potential regulatory hurdles.
-
-
Batch analytics pipeline
-
For population health, risk scoring, and retrospective analytics. Models run on batched data (nightly/weekly) and write results back to EHR or dashboard.
-
Pros: low real-time constraints, easier validation.
-
Cons: not suited for urgent decision support.
-
-
Edge inference
-
Models run locally on devices (edge servers, specialized appliances) or on-prem VMs. Particularly helpful where external connectivity is restricted.
-
Pros: privacy, low latency.
-
Cons: deployment complexity and hardware maintenance.
-
-
Federated learning / privacy-preserving approaches
-
Train models across multiple institutions without sharing raw patient data. Useful when building robust models across diverse populations.
-
Pros: better generalizability and privacy.
-
Cons: complexity, coordination overhead, and slower iteration cycles.
-
Core technical building blocks
-
Data ingestion and normalization
-
Interfaces: HL7 (v2), FHIR (R4), DICOM (imaging), LOINC, SNOMED, ICD-10, custom feeds.
-
Tasks: transform, normalize terminology, deduplicate, resolve patient identity, perform unit harmonization.
-
Tools: ETL frameworks, FHIR servers (HAPI FHIR), message brokers (Kafka), data lakes/warehouses.
-
-
Feature store
-
Central repository for production features (clinical risk factors, historical lab trends). Ensures feature parity between training and serving.
-
-
Model serving & MLOps
-
Model registry, CI/CD for models, versioning, A/B testing, canary releases.
-
Serving frameworks: TorchServe, TensorFlow Serving, Triton, or cloud managed ML endpoints.
-
-
Explainability & auditing
-
SHAP/LIME or clinically customized explanations that map to readable clinical features (e.g., “elevated creatinine and systolic BP contributed most to risk score”).
-
Immutable logging of inputs/outputs, user actions, model versions.
-
-
Clinical UI/UX layer
-
Contextual alerts, notifiers, in-line suggestions, one-click order sets, and editable AI draft notes. Respect alert fatigue principles.
-
-
Security, privacy & compliance
-
Encryption at rest/in transit, role-based access control, data minimization, audit logs, business associate agreements (BAAs) for vendors.
-
-
Monitoring & feedback loop
-
Production monitoring for data drift, concept drift, performance degradation, latency, and false positive/negative rates. Provide a clinician feedback channel to tag outputs.
-
Use cases and integration examples
Below are practical, prioritized use cases with integration notes.
1. AI-assisted clinical documentation (note generation)
-
What: Transcribe clinician–patient conversation or assemble structured data into a draft note (history, assessment, plan).
-
Integration:
-
Capture audio securely, transcribe with ASR, apply clinical NLP for entity extraction and context (negation, temporality).
-
Present a draft in the EHR note editor; clinician verifies and signs.
-
-
Key concerns: accuracy, hallucination mitigation, privacy (audio), audit trail linking audio → draft edits.
2. Real-time risk scoring and early warning
-
What: Predict sepsis, deterioration, readmission risk.
-
Integration:
-
Trigger model on new vitals/lab events via EHR event streams.
-
Surface risk with recommended actions and time horizon (e.g., “Sepsis risk: high — consider lactate, blood cultures”).
-
-
Key concerns: alert fatigue (tune thresholds), clinical protocols for escalation, clinical validation for local population.
3. Imaging & pathology augmentations
-
What: Tumor detection, fracture detection, or histopathology slide triage.
-
Integration:
-
From PACS/LIS, send DICOM or WSIs to model (on-prem or cloud).
-
Results annotate the imaging viewer in EHR or LIS and add structured findings to the report template.
-
-
Key concerns: regulatory clearance for diagnostic use, tight integration in radiology/pathology workflow.
4. Medication safety & decision support
-
What: Drug–drug interaction flags, suggested dosing adjustments based on renal function, allergy checks, duplicate therapy alerts.
-
Integration:
-
Real-time checks when prescribing; succinct recommendations with explanation and alternative suggestions; link to evidence.
-
-
Key concerns: override tracking, minimizing false positives, updating knowledge bases.
5. Revenue cycle & coding automation
-
What: Automated charge capture, coding suggestions, claim denial predictions.
-
Integration:
-
NLP processes notes to suggest ICD/CPT codes for coder review; RCM dashboards highlight likely denials.
-
-
Key concerns: auditability, compliance, audit trails for payer queries.
6. Patient triage and digital assistants
-
What: Patient-facing chatbots that integrate with EHR (appointments, med refills, symptom triage).
-
Integration:
-
Secure API access to appointment & med lists; record interactions to chart; escalate to clinician when needed.
-
-
Key concerns: clarity on bot limitations, documentation, consent.
Data strategy — the foundation
AI in EHRs is only as good as the data feeding it.
Data quality checklist
-
Completeness: Are key fields routinely populated? (e.g., vitals, problem list, meds)
-
Consistency: Do labs, units and codes follow standards?
-
Timeliness: Are events available in near real-time for clinical models?
-
Representativeness: Does training data reflect patient demographics and device variation?
-
Labeling fidelity: Are outcomes/labels audited by clinicians?
Practical steps
-
Inventory data sources (EHR tables, device streams, imaging, claims, genomics).
-
Standardize terminologies: adopt FHIR, LOINC, SNOMED, RxNorm.
-
Build a feature store so training and serving reuse the same logic.
-
Create annotated datasets for supervised tasks and allocate clinician time for labeling.
-
Implement ETL with streaming support (for real-time tasks) and batch pipelines (for cohort analytics).
Clinical validation & regulatory considerations
AI that influences care needs validation.
-
Define clear performance metrics before deployment: sensitivity, specificity, positive predictive value, calibration, decision impact, time saved.
-
Local validation: Models validated on external datasets should be tested on local historical data. Differences in population or devices often degrade performance.
-
Prospective pilot: Run in silent mode (no clinician alerting) to collect real-world performance, then phased active mode.
-
Regulatory compliance:
-
US: FDA pathways (SaMD guidance); some tools may need clearance/510(k).
-
Data privacy: HIPAA in the US; GDPR in EU for patient data handling.
-
Maintain documentation and audit trails for decisions and model versions.
-
-
Human-in-the-loop: For high-risk tasks, retain clinician final decision and track overrides.
UX & clinician adoption — design principles
AI only creates value when clinicians trust and use it.
-
Contextual relevance: show AI output only when it matters (in the right screen, for the right user role).
-
Concise & actionable: recommendations should be short and include “why” and “what to do”.
-
Transparency: provide an explanation focused on clinical features, not raw model internals.
-
Editable outputs: let clinicians correct AI suggestions (this creates feedback data).
-
Low friction: one-click actions (order sets, prefilled notes).
-
Training & champions: clinician champions should lead pilots and training sessions.
-
Feedback channel: easy mechanism to flag incorrect suggestions.
MLOps & lifecycle management
Operationalizing AI requires production practices similar to software engineering but tailored for models.
-
Versioning: model artifacts, datasets, feature engineering code, schema.
-
Continuous evaluation: track performance metrics in production; set drift detection alerts.
-
Canary & A/B testing: roll new models gradually.
-
Rollback & failover: ability to disable model or fall back to deterministic rules.
-
Explainability pipelines: compute SHAP values or equivalent at inference to record reason for outputs.
-
Retraining strategy: schedule periodic retrain or trigger retrain when performance dips.
-
Monitoring dashboards: latency, requests, error rates, prediction distributions, clinical metrics.
Security, privacy & compliance details
-
Encryption: TLS for transit, AES-256 (or equivalent) for storage.
-
Access control: strict role-based controls — clinicians only see predictions for patients they are treating.
-
Data minimization: send only necessary data to external services; consider tokenization or hashed identifiers.
-
BAAs: vendor contracts must include BAAs and security attestations.
-
Logging & forensics: immutable audit logs that record inputs, outputs, model version, user action.
-
Penetration testing: regular security testing, especially for any exposed APIs.
Explainability & trust
Black-box outputs will be rejected. Provide clinical explanations:
-
Map model features to clinical constructs (“recent creatinine rise -> higher AKI risk”).
-
Offer counterfactual suggestions (“If systolic BP lowered to X, predicted risk reduces by Y%”).
-
Include confidence bands and whether the input distribution is out-of-sample.
-
Document known blind spots (populations where model underperforms).
Measuring success — KPIs & monitoring
Define clear, measurable KPIs tied to business and clinical outcomes:
Clinical KPIs
-
Change in diagnostic accuracy (sensitivity/specificity).
-
Time saved per clinician (documentation time reduced).
-
Time to treatment for critical conditions.
-
Readmission rates and adverse events.
Operational KPIs
-
Appointment no-show reduction.
-
Revenue cycle improvements (reduction in denials, increased charge capture).
-
Average length of stay (LOS) reduction.
Adoption & UX KPIs
-
Usage rate of AI features (how often clinicians accept suggestions).
-
Override rates and reasons.
-
Time spent reviewing AI suggestions.
Safety & performance
-
Model drift alerts per month.
-
Incident reports linked to AI suggestions.
Typical implementation roadmap (12–24 weeks example)
Phase 0 — Discovery (Weeks 0–2)
-
Stakeholder mapping, select pilot use case, assemble cross-functional team (clinician, data engineer, SRE, privacy/legal).
-
Inventory data & access requirements.
Phase 1 — Data & MVP model (Weeks 3–8)
-
Build ETL/feature pipelines.
-
Train baseline model and perform retrospective validation on local data.
-
Design clinician UI mockups.
Phase 2 — Integration & silent pilot (Weeks 9–12)
-
Serve model in dev environment; integrate with EHR via API/Webhook or microservice.
-
Run in silent mode (outputs logged but not shown to clinicians). Collect metrics.
Phase 3 — Clinician pilot & iterative improvement (Weeks 13–20)
-
Deploy to a small clinical team with UI, collect feedback, track KPIs.
-
Tune thresholds, add explainability, reduce false positives.
Phase 4 — Scale & governance (Weeks 21–36)
-
Expand across departments, harden MLOps, implement retraining schedule, formalize governance and monitoring.
-
Prepare documentation for audit/regulation.
Phase 5 — Continuous improvement
-
Monitor production, retrain as needed, expand to new use cases.
Common pitfalls and how to avoid them
-
Rushing to production without local validation → run prospective silent pilots first.
-
Ignoring clinician workflow → co-design with end users and measure impact on time/decision.
-
Underinvesting in data cleaning → invest in data curation early.
-
Poor versioning & rollout strategy → adopt MLOps and maintain backward compatibility.
-
Overpromising AI capabilities → clearly communicate limitations to clinicians and patients.
-
Neglecting governance & compliance → include privacy, legal, and ethics teams from day one.
Technology recommendations (tooling & stack ideas)
-
Data & messaging: Kafka, Debezium (CDC), FHIR server (HAPI FHIR), DICOM routers.
-
Feature store: Feast, Tecton, or custom Redis/SQL based store.
-
Model training: PyTorch, TensorFlow, scikit-learn.
-
Serving / MLOps: MLflow (registry), Seldon, KFServing, Triton, or managed services (AWS SageMaker, GCP Vertex AI, Azure ML).
-
Explainability: SHAP library, ELI5, integrated interpreters.
-
Monitoring: Prometheus, Grafana, custom model-performance dashboards.
-
Security & compliance: Vault (secrets), encryption libraries, SIEM integration.
Example: simple architecture diagram (textual)
-
EHR event (lab result) →
-
Message bus (FHIR / HL7 -> Kafka) →
-
Feature pipeline (real-time feature computation; fetch historical values from feature store) →
-
Model inference service (internal microservice or cloud endpoint) →
-
Explainability module (compute top features) →
-
Decision service (apply thresholds and business rules) →
-
EHR UI (alert, suggested order set, or note draft) →
-
Logging & feedback (store input, output, clinician action) →
-
Monitoring & retrain pipeline (trigger retrain on drift)
Sample regulation & documentation checklist
-
Model specification and intended use description.
-
Performance metrics on development and local validation datasets.
-
Risk analysis and mitigation plan.
-
User training materials and decision support guidelines.
-
Audit logs for inputs, outputs, and clinician actions.
-
Post-market monitoring plan (continuous performance monitoring).
Final takeaways
-
Start small, measure, then scale. A focused pilot with a measurable clinical or operational outcome de-risks the journey and builds clinician trust.
-
Data quality beats model complexity. A simple, well-validated model on clean, representative data will outperform a sophisticated model on noisy data.
-
Integrate into workflows, don’t interrupt them. The most successful AI features are the ones clinicians adopt without friction.
-
Governance and transparency are essential. Treat AI in the EHR like any other medical device: document, monitor, and be ready to explain.
-
Make models living assets. Production monitoring, datasets versioning, and scheduled retraining are mandatory — not optional.
