Modern LLMs Compared: A Practical Guide for CTOs and Product Leaders
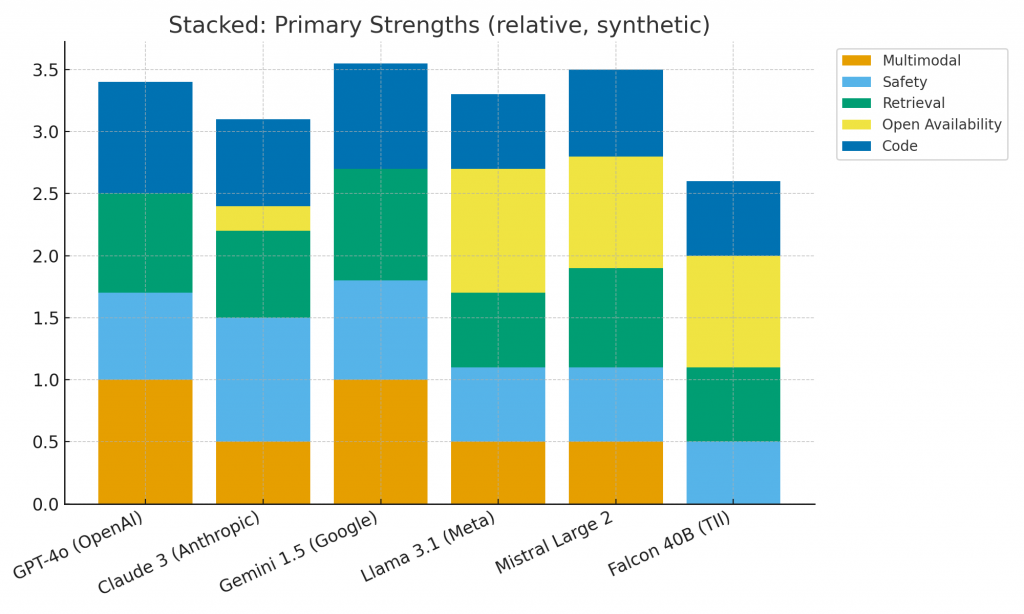
Modern LLMs now form several distinct families: managed multimodal leaders, safety-focused long-context models, open foundation models for self-hosting, and specialized/regional alternatives. Each class has strengths and trade-offs around capability, safety, context handling, cost, and deployability. Choosing the right model means matching product requirements to those trade-offs — not chasing raw benchmark numbers. This guide explains the differences, implications for architecture and governance, and offers a practical selection process you can use when evaluating models for production.
Executive snapshot
The commercially relevant LLM scene now breaks down roughly into these groups:
-
Managed multimodal leaders: strong at mixed-input tasks (text, images, audio) and provided as API services that include infrastructure, monitoring, and safety work.
-
Safety-oriented, long-context families: tailored for applications demanding conservative behavior and the ability to process very long documents in a single pass.
-
Open foundation models: weights you can host yourself, fine-tune, and run locally for cost or privacy reasons.
-
Niche and regional models: focused on particular languages, regulatory contexts, or hardware/latency constraints.
The correct choice depends on your priorities: do you need the best turnkey multimodal performance, the ability to host everything inside your network, an extremely long context window, or a heavily safety-tuned model? The rest of this piece walks through those questions, practical architecture patterns, governance needs, and an actionable decision checklist.
How this comparison was constructed
This is a practitioner-focused synthesis, not an exhaustive technical paper. I combined vendor descriptions, public model notes, independent reporting, and practical production perspectives to highlight the differences that matter when building real products: architecture, multimodal capabilities, context window size, alignment and safety posture, licensing/deployability, and operational economics. The goal is to translate those technical differences into the engineering and product trade-offs you’ll face in production.
Concise family profiles
Below are short practical profiles of the main families you’re likely to consider.
Managed multimodal leaders — when you want the best out of the box
These offerings provide high-quality generation across text and other media — often integrating vision and audio with text reasoning. They come as managed APIs, reducing infrastructure burden and bundling safety and monitoring features.
When to use them: If your product needs top-tier multimodal reasoning fast, and you prefer the vendor to manage scaling and many safety controls.
Trade-offs: Higher runtime costs and less control over data residency; limited or no ability to host the raw model yourself in many cases.
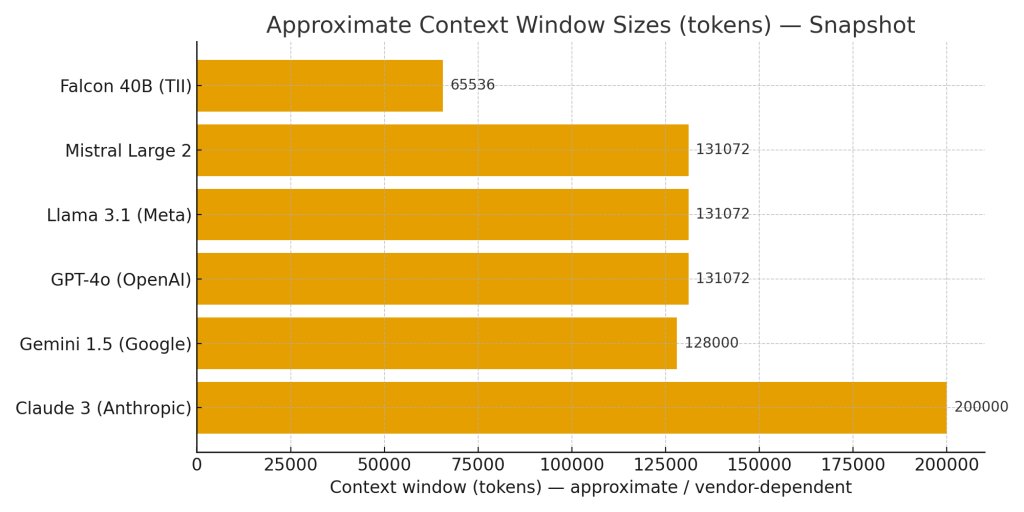
Safety-first, long-context models — when reliability and long documents matter
This class emphasizes conservative behavior, alignment with human norms, and the ability to process very large inputs in one interaction. They’re a strong fit for workflows that require processing long contracts, large legal or technical documents, or enterprise knowledge bases with minimal chunking.
When to use them: For regulated or high-stakes domains where auditability and predictable behavior matter, and for use cases that benefit from very large context tokens.
Trade-offs: They may provide more cautious responses and are usually delivered as managed services with enterprise-grade SLAs.
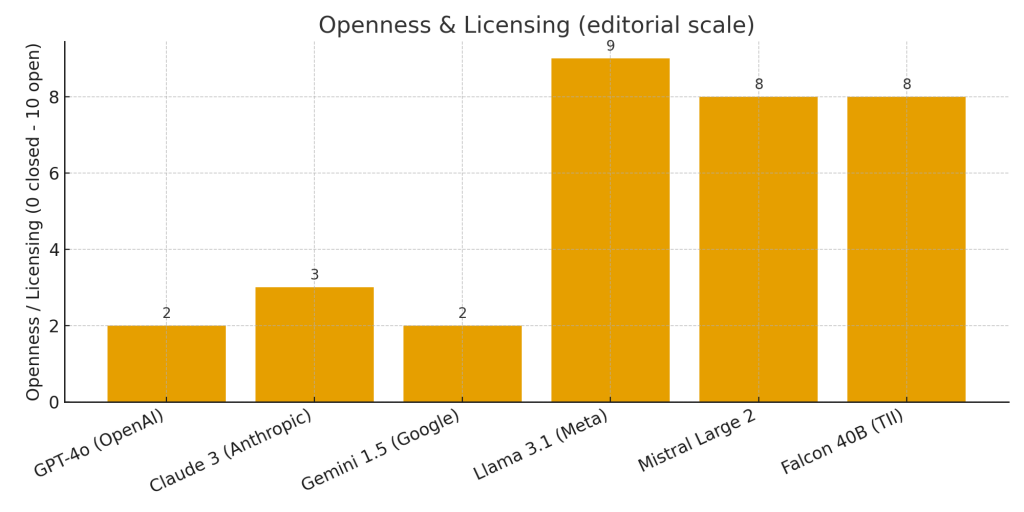
Open foundation models — when you must control hosting and cost
Open families are distributed as model weights and can be run on-prem or in private cloud. This makes them an attractive choice when you need strict control over data, want to avoid per-request API fees, or need to fine-tune models extensively.
When to use them: If you require data residency, aggressive cost control at high volume, or the freedom to customize model internals.
Trade-offs: You take on the operational burden for hosting, scaling, and implementing safety mechanisms that managed vendors provide.
Specialist and regional models — when fit and regulation are key
Certain models focus narrowly — language-specific capabilities, regional compliance, or deployment efficiency on limited hardware. These are worth considering for local-market or hardware-constrained products.
When to use them: Your focus is narrow (particular language or regulatory regime) or you must run on constrained devices.
Trade-offs: You might sacrifice some general-purpose quality and find smaller ecosystems for tooling and community knowledge.
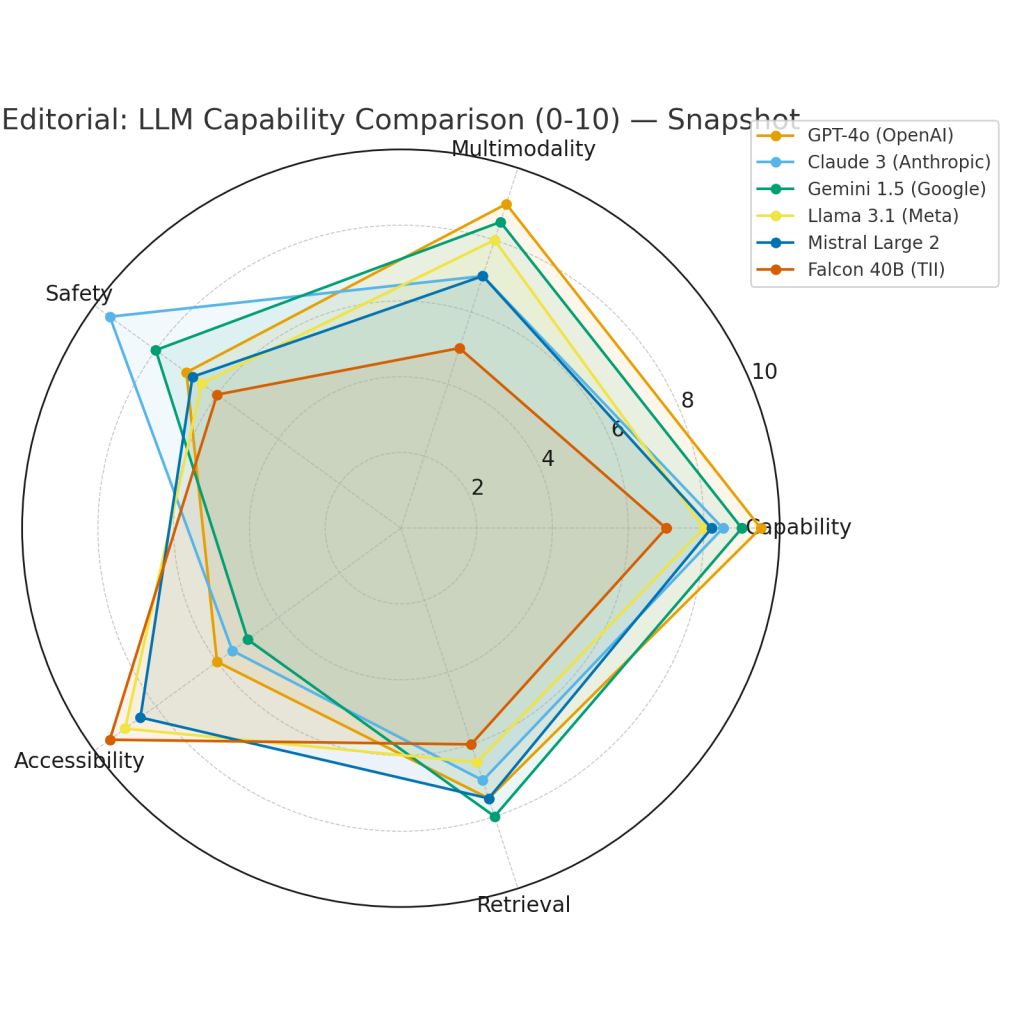
The product-relevant comparison axes
Evaluate models by practical, product-focused dimensions rather than abstract benchmark scores.
Capability and reasoning
How well a model handles multi-step reasoning, creative generation, code, and complex instructions. Proprietary multimodal leaders often lead in general-purpose benchmarks; however, many open models are competitive on domain-specific tasks once fine-tuned.
Multimodality
If your application needs image, audio, or multi-format reasoning, prefer a model that natively supports those inputs. Otherwise, you’ll need additional engineering to bridge modalities.
Context length
Some models accept massive context windows — hundreds of thousands of tokens. Very large contexts simplify long-document workflows but increase request cost and latency. For many heavy-document applications, long-context models reduce complexity by removing the need for an elaborate retrieval/aggregation pipeline.
Safety and alignment
Certain offerings are explicitly tuned to be conservative, reduce harmful outputs, and follow safety constraints. When you’re building tools that surface critical advice, that tuning can reduce the amount of bespoke safety infrastructure you must build.
Deployability and control
Do you need to host the model inside your network? Open models allow that; managed models often do not, unless negotiated. Control matters for privacy, compliance, and IP-sensitive workloads.
Cost and operations
Managed APIs bill per request or per token. Self-hosted models require GPUs, ops engineering, and staff. The economic break-even depends on traffic volume, latency targets, and tolerance for operational complexity.
Benchmarks and factuality: why real data matters
Benchmarks give directional insight, but the only reliable evaluation is a POC on your data. Hallucinations — plausible-sounding but incorrect outputs — remain a concern across all models. For systems that must be factual, combine retrieval and grounding with independent verification rather than relying solely on a model’s raw output. The model that scores best on leaderboards is not always the one that will produce the fewest factual errors for your dataset.
Cost trade-offs and hybrid economics
Consider both sides of the ledger:
-
Managed models: Faster time-to-market and less ops debt, but ongoing per-call costs that can scale quickly with usage.
-
Open/self-hosted models: Lower marginal cost for high-volume inference but upfront and recurring infrastructure and staffing expenses.
-
Hybrid patterns: Many teams start with managed APIs for development speed, then migrate volume-bound, non-sensitive workloads to self-hosted models for cost efficiency.
Always build a cost sensitivity model (per-request, monthly volume, storage, team time) when choosing your long-term plan.
Factuality and mitigation strategies
To reduce hallucinations and increase trustworthiness:
-
Retrieval-augmented generation (RAG): Use a search layer to ground model responses in source documents.
-
Structured outputs: Force models to return typed results or JSON, then validate them.
-
Cross-checks: Ask the model to verify claims against authoritative sources or use an independent fact-checker.
-
Guarded prompting and instructions: Craft prompts that constrain speculation and request citations.
-
Human review: Route high-risk outputs to reviewers before actioning them.
In most enterprise systems, the correct approach is to treat model outputs as suggestions that must pass verification before being used in critical paths.
How context windows change design
Large context windows allow feeding entire documents into the model, simplifying workflows such as summarization, long-form reasoning, and consolidated Q&A. The upside is reduced engineering complexity. The downsides are higher per-request cost, potentially slower response times, and the need to manage very large inputs carefully. Choose large-context models when the benefit of processing whole documents outweighs these costs.
Licensing and operational implications
If you need to control model behavior, data flows, or fine-tune heavily, open models are more appropriate. Managed vendors shorten the path to production but often come with contractual restrictions around data usage, retraining, and export. For regulated data or highly sensitive IP, prioritize models and vendors that support private deployments or provide contractual assurances about data handling.
Practical product patterns and where each family excels
-
Customer-facing assistants and creative tools: Managed multimodal leaders give the best out-of-the-box performance.
-
Research and long-document workflows: Safety-focused long-context models and large-window offerings are preferable.
-
High-volume internal automations: Self-hosted open models can be more cost-effective.
-
Edge and offline use cases: Distilled open models are typically necessary.
Often the best system combines multiple model families: use an open model for high-volume lightweight tasks and a managed multimodal model for heavy-lift reasoning or image/audio tasks.
Governance and production-hardening checklist
Before going live with an LLM-driven feature, implement these safeguards:
-
Provenance and logging: Record which model version served a request, what the prompt was (or a hashed representation), and the final output.
-
Verification layer: Ensure factual claims are backed by retrieval or other checks.
-
Human-in-the-loop policy: Define thresholds and SLAs where human review is required.
-
Monitoring and drift detection: Track hallucination rates, latency, and cost per request.
-
Incident rollback plan: Use feature flags and an emergency disablement path for problematic behavior.
-
Legal review: Check licensing and contractual implications for the model you plan to use.
Managed vendors sometimes supply tooling that covers some of these needs; with open models you must build them yourself.
Recommended architecture patterns
Here are practical, battle-tested patterns:
-
RAG + verifier microservice: Retrieval provides evidence, the model drafts the response, and a verifier confirms the claims before exposure.
-
Split inference: Run a small on-device or local model for quick initial answers and escalate to a large model for heavy reasoning.
-
Adapter layer: Abstract your model calls behind a thin interface that hides vendor-specific quirks and enables provider swaps.
-
Canary releases with human sampling: Roll out new models to a fraction of traffic while collecting human review for a period.
These patterns help you manage cost, risk, and vendor lock-in while delivering reliable user experiences.
Use-case examples: which family to pick
-
Multi-format customer help that includes images and voice: Managed multimodal providers deliver the fastest, most polished results.
-
Legal and contract analysis across very long documents: Long-context, safety-oriented models let you reason across entire files without stitching.
-
High-volume internal extraction and classification jobs: Self-hosted open models provide the best long-term economics.
-
Localized or compliance-sensitive deployments: Specialist or regional models tuned to local languages or regulations are often the right choice.
Remember: combine models when needed. A hybrid that uses multiple model types can often provide the best trade-offs.
Limitations and important caveats
-
The landscape evolves rapidly — features and pricing change often. Revalidate vendor claims before committing.
-
Benchmarks are only a starting point; real-world data matters most. Run domain-specific tests.
-
Self-hosting saves on marginal inference cost but increases operational overhead and responsibility for security and alignment.
Final practical recommendations
-
Prototype quickly. A focused two-week proof-of-concept using real inputs will reveal most surprises.
-
Wrap model calls in an abstraction layer. This reduces migration friction if you change providers later.
-
Use hybrid economics. Managed models for development speed; move high-volume, non-sensitive workloads on-prem as needed.
-
Verify before you act. Treat model outputs as provisional and validate critical facts.
-
Embed governance from day one. Logging, human review criteria, and rollback mechanisms should be integrated before launch.
